栏目分类
你的位置:htt192168101.1登录网址 > htt192168101.1登录网址介绍 >
编辑:LRST
【新智元导读】GenXD模型结合CamVid-30K数据集突破了3D和4D场景生成的挑战,能从单张图片生成逼真的动态3D和4D场景。这一进展为虚拟世界构建带来新的可能性,让动态场景的生成更加快速和真实。
在我们熟知的2D图像和视频生成技术蓬勃发展之际,3D和4D的世界依然是前沿科技的「无人区」。
面对真实场景中复杂的物体运动和视角变化,3D、4D生成一直面临数据和模型设计的双重瓶颈。然而,一项令人振奋的突破即将改变这一现状!
近日,新加坡国立大学(NUS)的研究人员提出了一种全新的生成框架——GenXD,不但能生成极具真实感的3D场景,还实现了从相机视角和物体图片中「生长」出逼真的4D动态场景。

项目主页:https://gen-x-d.github.io/
论文链接:https://arxiv.org/abs/2411.02319
代码链接:https://github.com/HeliosZhao/GenXD
GenXD能够实现单图片静态虚拟物体和场景的生成,实现高质量的3D内容创作:



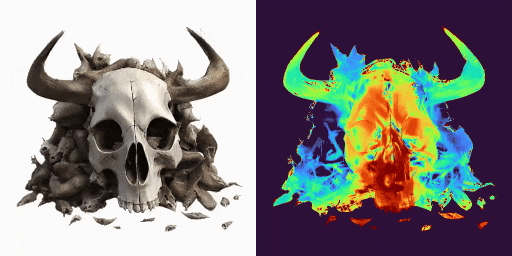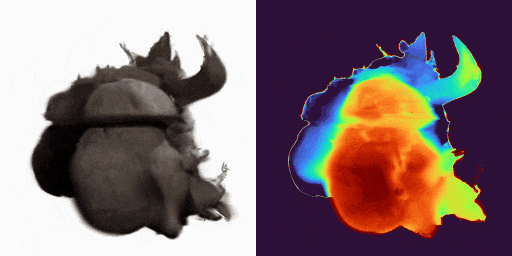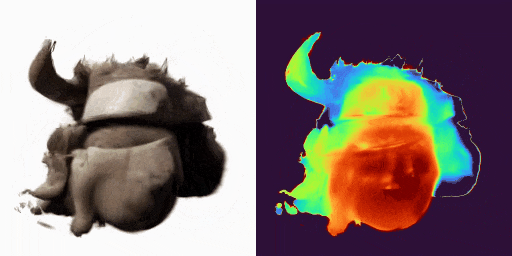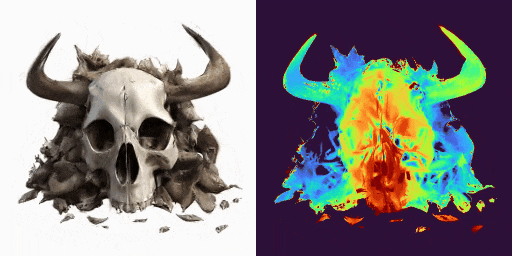
GenXD也能够实现稀疏图片场景的重建,作为先验完善3D重建任务:


GenXD可以实现单图4D生成,生成任意时刻以及任意视角:
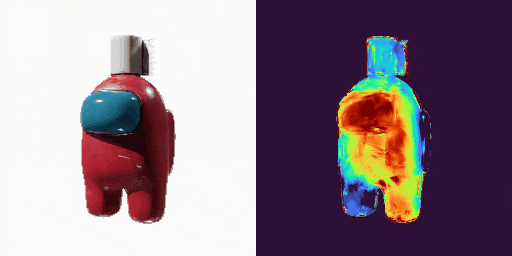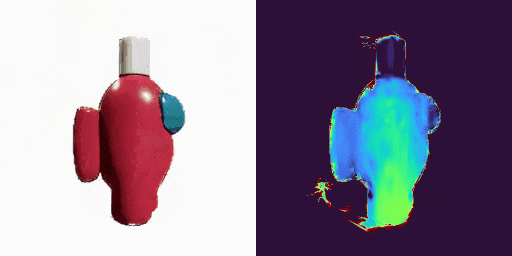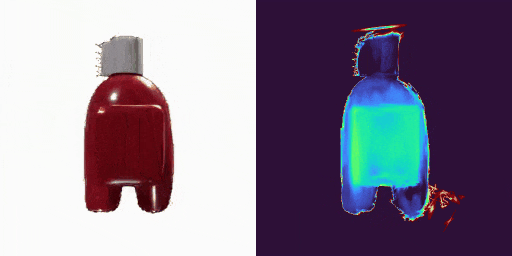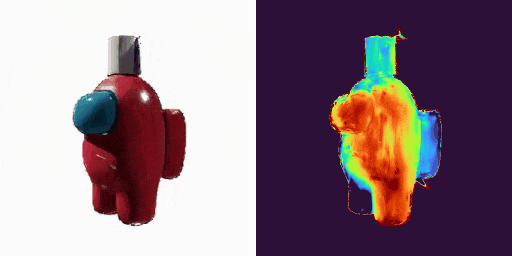
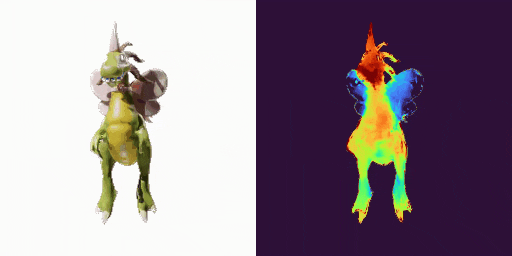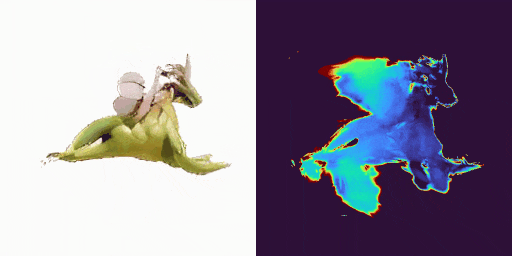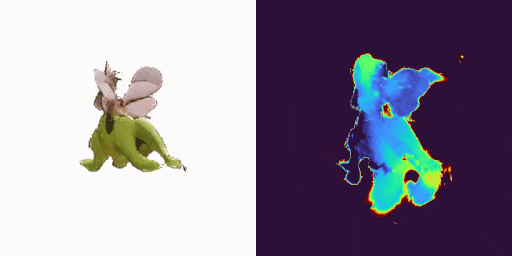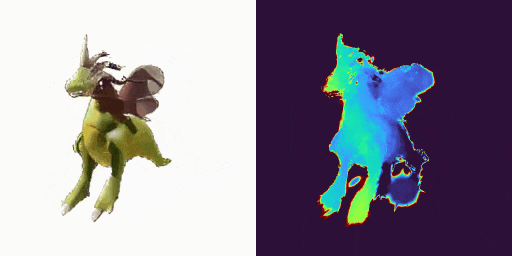
GenXD也能够助力视频插帧和可控视频生成,使用多图和相机路径作为控制信号:
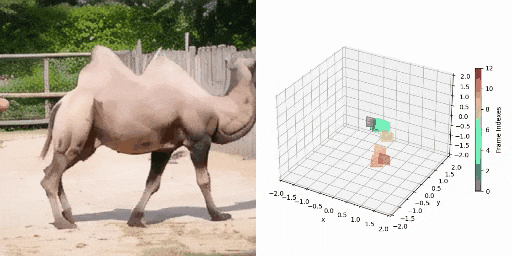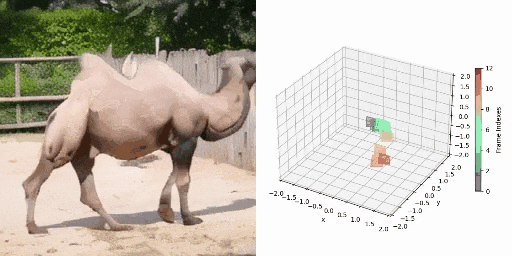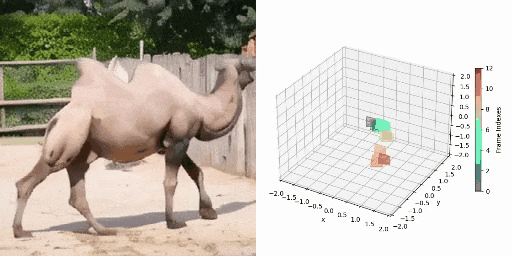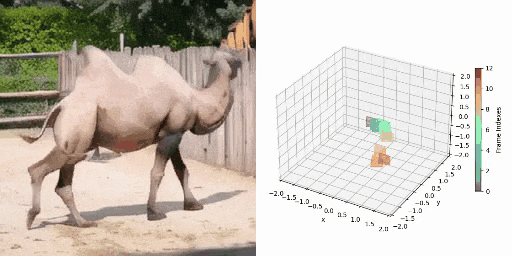

CamVid-30K 4D数据构建
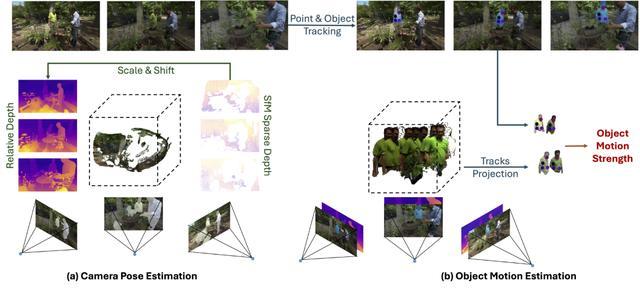
图1 数据标注
在动态3D任务的发展中,缺乏大规模4D场景数据一直是一个关键瓶颈。这不仅影响到4D生成、动态相机姿态估计等任务,也限制了可控视频生成等应用的进展。
为了解决这一难题,研究团队推出了一个高质量4D数据集——CamVid-30K,为未来的动态3D任务奠定了坚实基础。
CamVid-30K数据集的创建过程包括了一系列精细的步骤。首先,研究人员使用基于运动恢复结构(SfM)的方法来估计相机姿态。
SfM通过从多张图像的投影中重建3D结构,其中包括特征检测与提取、特征匹配、3D重建与相机姿态估计等关键步骤。
为了确保准确性,特征匹配仅限于静态场景部分,以避免动态物体误导相机的运动估计。
与之前方法不同的是,CamVid-30K使用了一种实例分割模型,将所有可能移动的像素进行分割。
相比早期的运动分割模块,该实例分割方法具备更强的泛化能力,特别是在复杂场景下更为适用。随后,利用改进的Particle-SfM对静态背景进行处理,最终生成精准的相机姿态和稀疏点云信息。
为进一步筛选出真正的动态场景,CamVid-30K还引入了运动强度指标来识别物体的真实运动。通过对齐深度投影,将动态物体在3D空间中进行重投影,以便检测位移,确保所包含的场景具有丰富的动态细节。这一过程确保了CamVid-30K不仅包含相机的运动信息,还捕捉到了物体本身的运动,使其成为高质量的4D数据资源。
模型架构
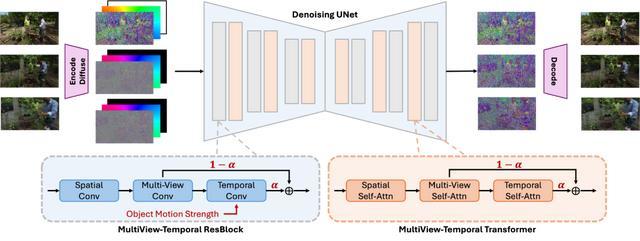
图2 整体框架
为了实现更自然的3D和4D场景生成,GenXD使用隐变量扩散模型(LDM),生成出符合相机视角和时间序列的场景图像。此外,GenXD提出多视角-时间层,将3D和时间信息有效解耦和融合。
对于相机视角信息,GenXD使用每个视角下的Plucker Ray作为控制信号。而对于单张或多张图像信息,GenXD使用掩码隐变量条件(mask latent conditioning)方式利用图像信息。
该方法在图像条件输入时具有三大优势:首先,无需对模型参数进行修改,便可以支持任意视角输入;其次,在多视图生成或视频生成过程中,无需固定条件帧的位置,确保了更大的灵活性;最后,省去了额外的条件嵌入,从而减少了模型参数量。这种设计不仅使得GenXD更高效,还可以处理复杂的多视角输入场景。
为了实现3D和4D的生成,GenXD引入了多视角-时间模块,分别对多视角信息和时间信息进行建模。通过设计多视角层与时间层,GenXD可以在3D生成时忽略时间信息,而在4D生成时引入多视角与时间信息的融合。
此外,模型采用了alpha融合策略,利用一个可学习的融合权重来控制4D生成的多视角和时间信息融合效果,从而实现更精准的动态场景生成。
此外,为了解决运动控制的问题,GenXD将CamVid-30K数据集中提供的运动强度引入多视角-时间ResBlock中。这样,模型可以准确地表达物体运动,从而在生成的场景中体现更自然的动态效果。
实验结果
GenXD在单视角4D生成,相机控制的视频生成,单视角3D生成以及少视角3D重建任务上均可用,并取得了很好的效果。
单视角4D生成
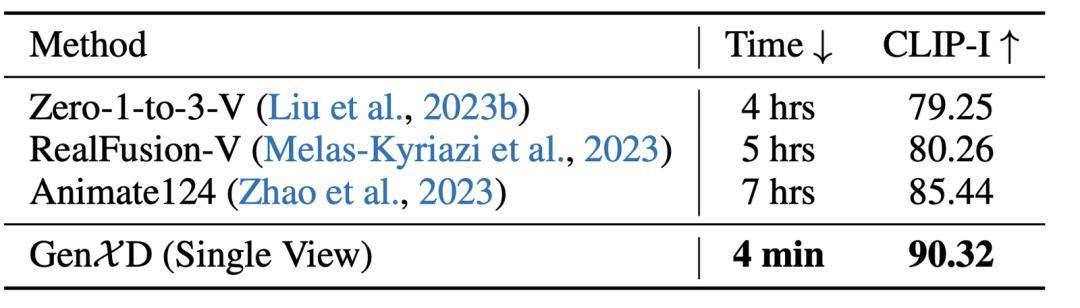
表1 单视角4D生成
对于单视角4D生成,GenXD首先生成4D视频,然后使用生成的视频优化4D高斯泼溅网络因此,与过去基于SDS的方法相比,GenXD有更快的优化速度,也有更好的效果。
相机控制的视频生成
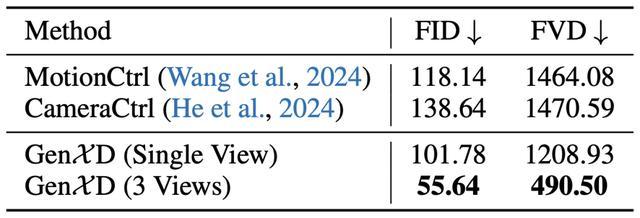
表2 相机控制的视频生成
GenXD也与过去相机控制的运动生成方法进行了比较,过去的方法只能使用单张图片作为条件,无法实现视频插帧的功能。但单图条件下,GenXD超越过去的方法, 若使用多图作为条件,GenXD的效果可以得到更大的提升。
单视角3D生成
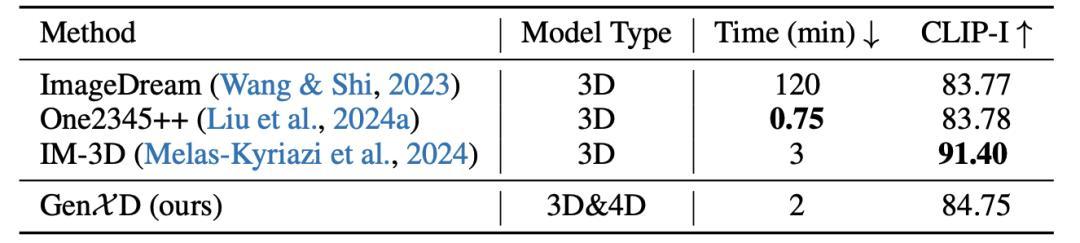
表3 单视角3D生成

图3 单视角3D生成
GenXD也在3D合成物体生成任务上进行了评估。在此任务上,GenXD首先生成360度视频,并利用此视频优化3D高斯泼溅网络。过去的方法在合成物体3D数据集上单独训练,而GenXD使用了不同分布的真实数据和4D数据。即使如此,GenXD也与过去的方法有相近的效果。此外,从可视化结果来看,GenXD没有过去方法常见的过度平滑和过度饱和问题。
少视角3D重建
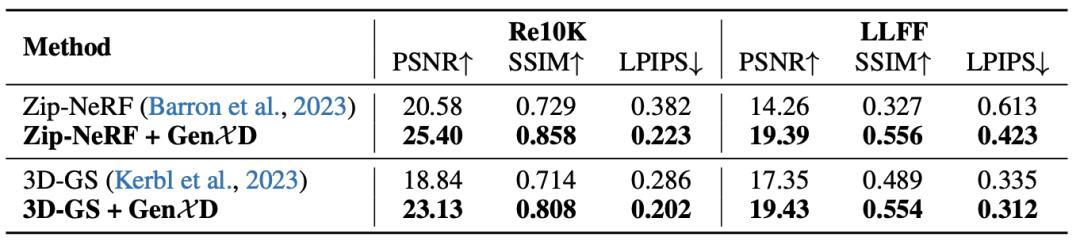
表4 少视角3D重建

图4 少视角3D重建
GenXD可以使用多张图片作为条件,生成尺度一致的3D内容。因此,GenXD可以将生成的图片作为补充,提升少视角3D重建的效果。在此项目中,GenXD与两个重建网络(ZipNeRF和3DGS)相结合,极大地提升重建的效果。
运动控制

图5 运动控制
数据标注管线中提出了运动强度的概念,并且被引入到多视角-时间ResBlock里进行运动控制。图5可视化了运动控制的效果。使用同样的图片和相机条件,增大运动强度可以提高物体运动的速度,从而实现可控生成。
总结
GenXD模型和CamVid-30K数据集为3D和4D生成领域带来了全新突破。通过设计多视角-时间模块并引入掩码隐变量条件,GenXD不仅能够解耦相机和物体的运动,还可以支持任意数量的条件视图输入。
GenXD展示了在各类应用中的强大适应性,且在多项任务中达到了与现有方法相当或更优的表现。这一成果为未来的3D和4D生成任务奠定了坚实的基础,预示着虚拟世界构建与动态场景生成的无限可能。
参考资料:
https://gen-x-d.github.io/
下一篇:没有了